Reference Fabric Area Intersection Weights and Rescaled Attributes
PRELIMINARY SUBJECT TO REVISION
Dates
Publication Date
2024
Time Period
2024
Citation
Ellie White, Michael E. Wieczorek, and Andy Bock, 2024, Reference Fabric Area Intersection Weights: USGS, https://doi.org/10.5066/xxxxxxxx.
Summary
This data release contains a series of tabular crosswalks with spatial weighting for facilitating the conversion of spatial data between different hydrographic networks and spatial units. The child items in this repository contain the following types of intersections: 1) polygon to polygon 2) polygon to raster 3) flowline to polygon 4) point to network The format of these files is zipped csv containing three columns: id_source, id_target, and weight where: id_source is the case insensitive identifier of the polygons requiring weights. id_target is the case insensitive identifer of the polygons of the target data to be intersected with the id_source. weight (w) is the fractional overlap of id_source to id_target, calculated as: w = [...]
Summary
This data release contains a series of tabular crosswalks with spatial weighting for facilitating the conversion of spatial data between different hydrographic networks and spatial units. The child items in this repository contain the following types of intersections: 1) polygon to polygon 2) polygon to raster 3) flowline to polygon 4) point to network The format of these files is zipped csv containing three columns: id_source, id_target, and weight where: id_source is the case insensitive identifier of the polygons requiring weights. id_target is the case insensitive identifer of the polygons of the target data to be intersected with the id_source. weight (w) is the fractional overlap of id_source to id_target, calculated as: w = (area of intersection) / (area of id_target) Source and target datasets are specifically selected as those required to fulfill national program objectives. Additional details for each of these can be found in the metadata underneath each child item.
A common workflow in geospatial hydrology is to interpolate geospatial values from one set of polygonal zonal features to another. This can be a computational and time consuming undertaking. This data release provides an easier, faster, and less computationally intensive way, to get a close estimate of the values needed. In the figure below, the red polygon represents a feature where data is needed from the two blue polygons. By using the amount of overlap between the two blue polygons, data for the red polygon can be estimated by rescaling those attributes with a simple weighted mean or other aggregation methods that make sense for the data in question.
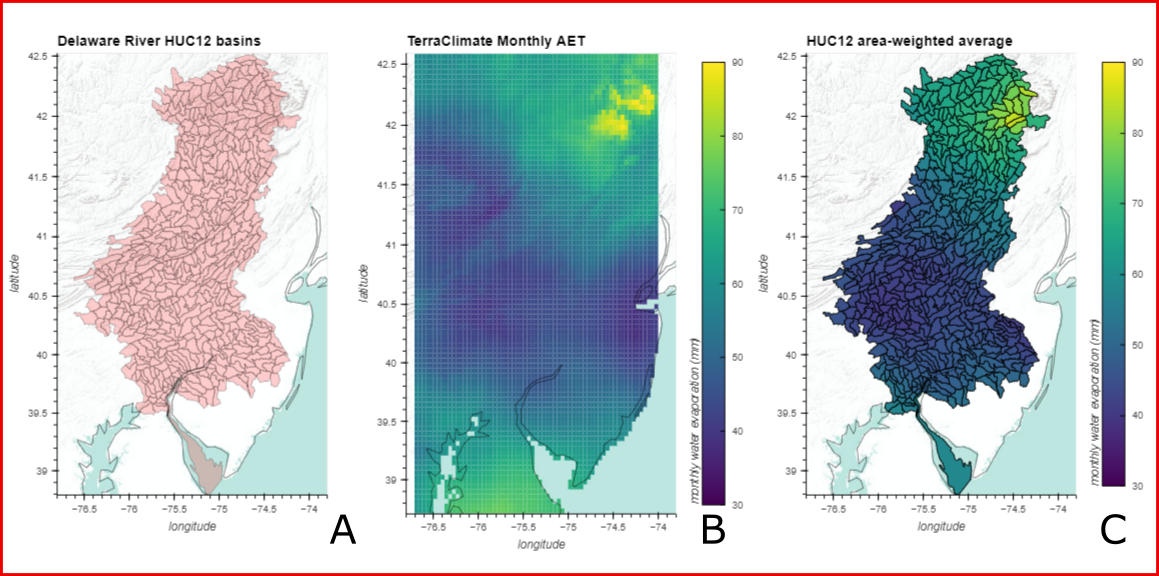
There are many high value data, for example climatic data, that resides in raster format that are used in countless projects needing information attributed to zonal features such as HUC12 watershed boundaries.. The figure below illustrates such a grid-to-polygon interpolation. A) Huc12 basins for Delaware River Watershed. B) Gridded monthly water evaporation amount (mm) from TerraClimate dataset. C) Area-weighted-average interpolation of gridded TerraClimate data to Huc12 polygons.
This data release contains a series of tabular crosswalks with spatial weighting for facilitating the conversion of commonly used spatial data between various well used hydrographic networks and spatial units. The child items in this repository contain the following types of these intersections:
polygon to polygon
polygon to raster
flowline to polygon
flowline to flowline
The format of these files is zipped csv contain three columns:
id_source: the identifier of the polygons requiring weights.
id_target: the identifer of the polygons of the target data to be intersected with the id_source
weight (w): the fractional overlap of id_source to id_target
Additional details for each of these can be found in the metadata underneath each child item.
A common workflow in geospatial hydrology is to interpolate geospatial values from one set of zonal features to another. These files provide the weights, or the "crosswalk", to be used to interpolate previously calculated attributes of one set of features to another. There are a number of high-priority national datasets derived at different scales for different purposes that are used to assess water quality and quantity, and their impacts of economics, infrastructure, and society. In the past, many of these datasets were built without consideration for sustainable data integration and compatibility. This resulted in many users developing workflows to integrate or crosswalk these datasets in different processing environments. Many of these workflows were done manually, or aren’t scaleable or re-usable. To complicate things further, there are multiple snapshots and versions of some datasets, resulting in the possibility that many users may have crosswalked to different deprecated versions of the same dataset. This data release aims to provide clarity and baseline for these data integrations by 1) establishing a location for authoritative citations and locations of national-scale datasets used for analysis or reporting for national USGS priorities (Miller and others, 2020), 2) defining common types and formats of crosswalk for gridded, polygon, polyline, and point data, 3) providing re-usable and re-scalable workflows developed in R and Python to establish consistent formats and functionality to crosswalk a source dataset to a target dataset. These workflows include links to source repositories and use cases to demonstrate use, and 4) Publishing crosswalks for datasets defined in #1 derived with principles established in #2 and #3. This data release will be maintained and updated as new national priority datasets are identified.